.
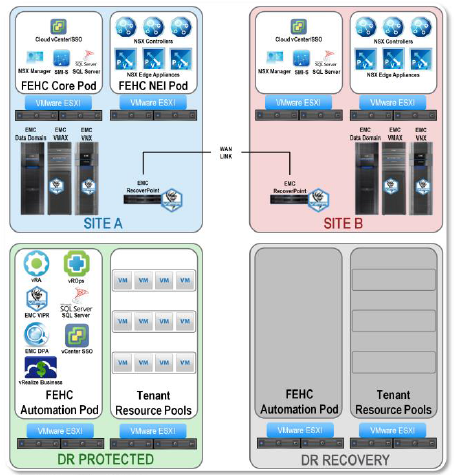
In the Federation Enterprise Hybrid Cloud v3.0, the foundation architecture has been changed to match the disaster recovery (DR) architecture from v2.5.1

Specifically, this means that an additional SSO and SQL server are deployed in the Automation Pod, allowing the other components in the Automation pod to fail over and still have access to those services.
This change allows customers to add DR functionality at a later time without having to make any architectural changes to the underlying infrastructure.
This change allows customers to add DR functionality at a later time without having to make any architectural changes to the underlying infrastructure.

Protected sites can now be used as recovery sites as well, allowing for either site to fail while retaining the ability to provision new resources.
In this example, the site in Phoenix serves as the recovery site for Boston, and vice versa. If the Boston site were to experience a failure, the Boston resources could be activated in Phoenix as part of the disaster recovery protocol.
If the Boston site remained down for an extended amount of time, new resources that are intended to be run in Boston could be provisioned at the Phoenix recovery site in the interim.
When the Boston site comes back online, the newly created resources could then be replicated to Boston and set as “protected” as if they had been originally created there. While all of this is taking place, operations in Phoenix are unaffected.
In this example, the site in Phoenix serves as the recovery site for Boston, and vice versa. If the Boston site were to experience a failure, the Boston resources could be activated in Phoenix as part of the disaster recovery protocol.
If the Boston site remained down for an extended amount of time, new resources that are intended to be run in Boston could be provisioned at the Phoenix recovery site in the interim.
When the Boston site comes back online, the newly created resources could then be replicated to Boston and set as “protected” as if they had been originally created there. While all of this is taking place, operations in Phoenix are unaffected.

In the Federation Enterprise Hybrid Cloud v3.0, a new Catalog Item was created that allows us to pair clusters from within vRealize Automation. This workflow allows us to set the properties and key values that are necessary for the cluster to function within a DR environment.
This was done manually before. Now, it is automated in a workflow/catalog item.
Once the cluster pair is created, it is still required to manually create the recovery plan in SRM based on the cluster name and properties.
This was done manually before. Now, it is automated in a workflow/catalog item.
Once the cluster pair is created, it is still required to manually create the recovery plan in SRM based on the cluster name and properties.
.
.
..














































